Shoot-Bounce-3D: Single-Shot Occlusion-Aware 3D from Lidar by Decomposing Two-Bounce Light
Abstract
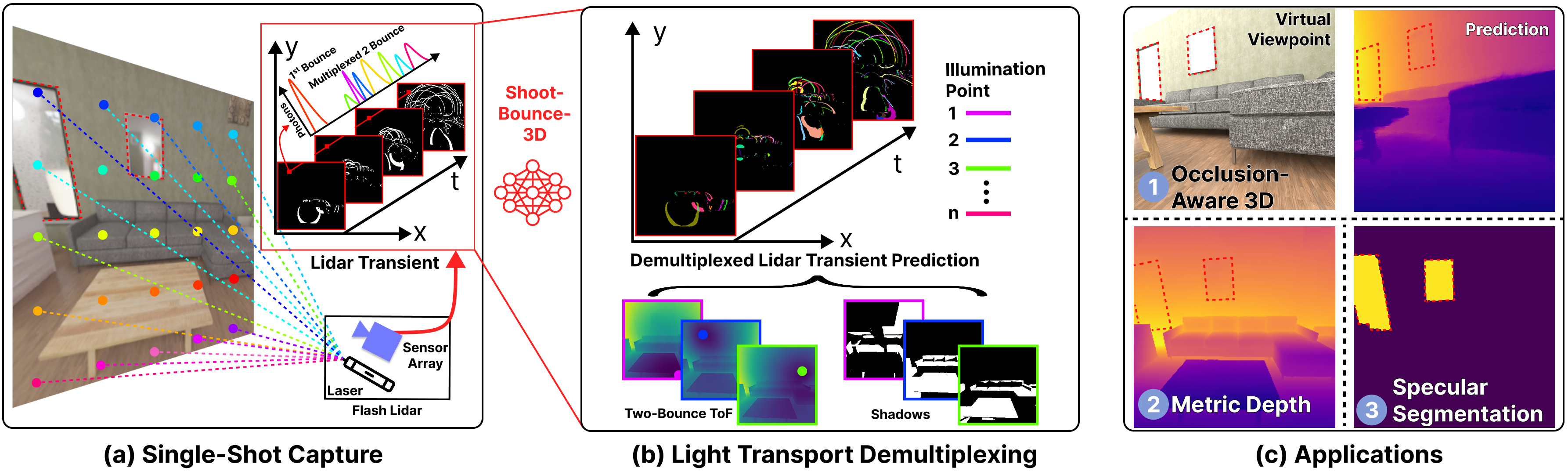
3D scene reconstruction from a single measurement is challenging, especially in the presence of occluded regions and specular materials, such as mirrors. We address these challenges by leveraging single-photon lidars. These lidars estimate depth from light that is emitted into the scene and reflected directly back to the sensor. However, they can also measure light that bounces multiple times in the scene before reaching the sensor. This multi-bounce light contains additional information that can be used to recover dense depth, occluded geometry, and material properties. Prior work with single-photon lidar, however, has only demonstrated these use cases when a laser sequentially illuminates one scene point at a time. We instead focus on the more practical - and challenging - scenario of illuminating multiple scene points simultaneously. The complexity of light transport due to the combined effects of multiplexed illumination, two-bounce light, shadows, and specular reflections is challenging to invert analytically. Instead, we propose a data-driven method to invert light transport in single-photon lidar. To enable this approach, we create the first large-scale simulated dataset of ~100k lidar transients for indoor scenes. We use this dataset to learn a prior on complex light transport, enabling measured two-bounce light to be decomposed into the constituent contributions from each laser spot. Finally, we experimentally demonstrate how this decomposed light can be used to infer 3D geometry in scenes with occlusions and mirrors from a single measurement. We plan to release our dataset to drive future research.
Results
3D Reconstruction
Top: Input View | Bottom: 3D Reconstruction





3D reconstruction results of both visible and occluded regions using Shoot-Bounce-3D. Please note SB3D only recovers geometry in the camera's field of view, hence some floaters, artifacts, and holes are visible in regions rendered beyond the training view.
Demultiplexing
Multiplexed Measurement Prediction
Predicted light in flight of 2-bounce light from Shoot-Bounce-3D (Right) compared to ground truth (Left). Each color in the prediction corresponds to light from a different illumination point that has been separated by our model. Predicted 2-bounce light in flight is created by masking 2-bounce ToF by shadow masks for each illumination point and rendering the ToF as binary frames across time.
Real-World Results
Light in Flight Measurement
Shown above is the light in flight video of the scene used for real-world validation. The video is played at 8 ps resolution, but downsampled temporally to 32 ps before inference.
Real-World Demultiplexing
Shown above are light in flight transients for four demultiplexed illumination points. The video is played at 32 ps resolution.
Citation
@inproceedings{ShootBounce3D,
author = {Klinghoffer, Tzofi and
Somasundaram, Siddharth and
Xiang, Xiaoyu and
Fan, Yuchen and
Richardt, Christian and
Dave, Akshat and
Raskar, Ramesh and
Ranjan, Rakesh},
title = {{Shoot-Bounce-3D}: Single-Shot Occlusion-Aware 3D from Lidar by Decomposing Two-Bounce Light},
booktitle = {SIGGRAPH Asia},
year = {2025},
url = {https://shoot-bounce-3d.github.io},
}